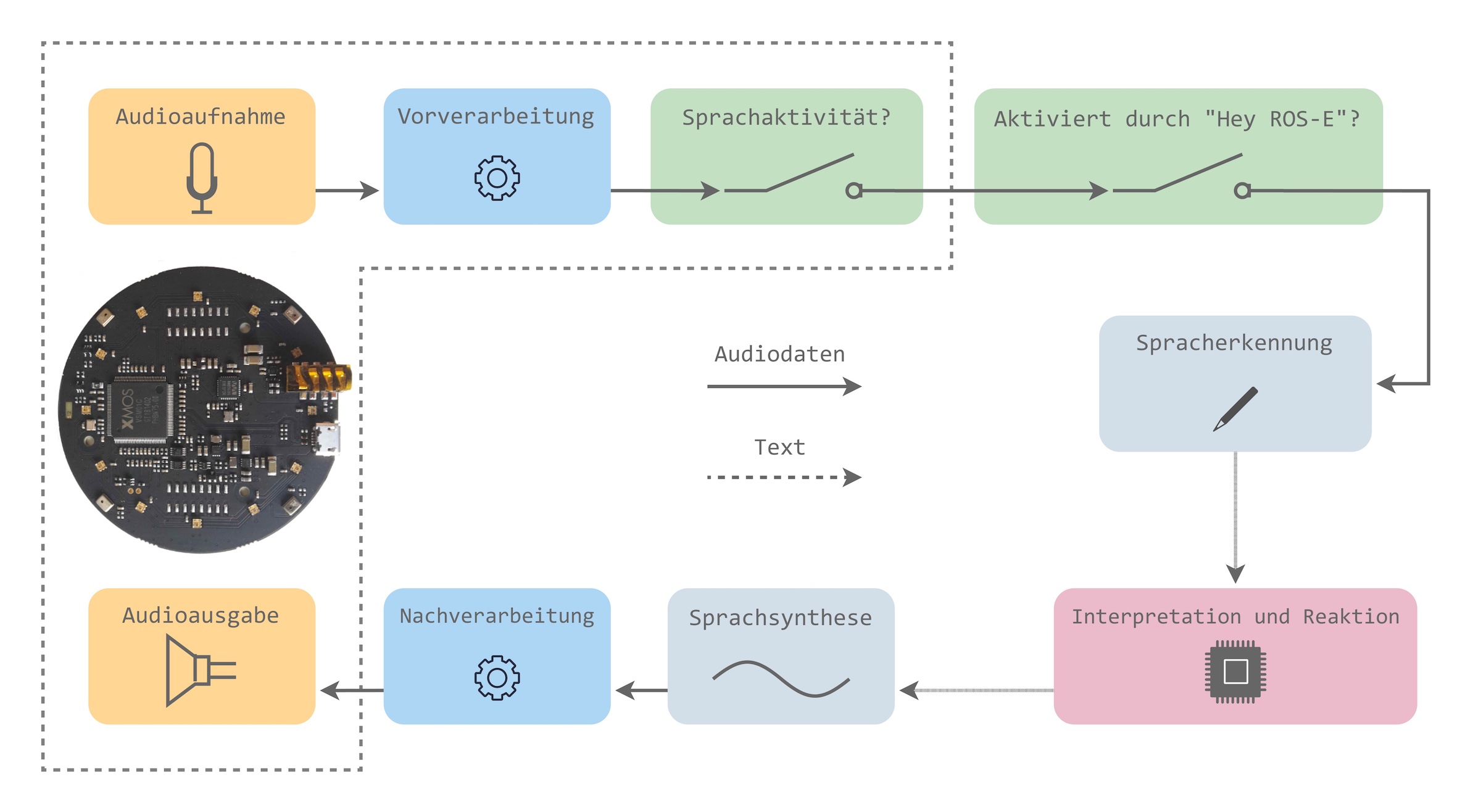
Katheter, Sonde oder doch ein Zugang?
Im Rahmen der Erstellung eines KI-Systems zur Informationssuche für die Pflege wurde ein spezielles IR (Information Retrieval) Modell entwickelt. Dieses System verbessert die zielgerichtete Suche in unstrukturierten Datenbeständen. Sowohl kurze, Keyword basierte Formulierungen als auch vollständige Fragen sind anwendbar. Mit dem entwickelten Ansatz konnte eine deutliche Verbesserung des Information Retrieval für Deutsch gegenüber bisherigen Ansätzen erreicht werden (um bis zu 14% Punkte).
Information Retrieval als Basis von Textsuche
„Wie reinigt man den gelegten Zugang?“ Nun, eine Person nimmt sich einen Wischlappen, befeuchtet diesen und wischt die Tür von oben bis unten ab, bis der Dreck entfernt ist. Irgendwie passen Frage und Antwort nicht zusammen? Richtig, denn beim Lesen bzw. Interpretieren erscheint die Kombination aus „etwas legen + Zugang“ nicht stimmig, um eine Interpretation mit Zugang/Eingang/Tür zuzulassen. Mit etwas Vorwissen lässt sich schlussfolgern, dass der Kontext im Bereich der medizinischen Versorgung anzusiedeln ist. Konkret wird erfragt, wie der Katheter einer Person gereinigt werden kann, beispielsweise um diesen zu desinfizieren. Aber die Beweggründe sind eigentlich unwichtig, denn was viel mehr interessiert, ist die korrekte Kontextualisierung und korrekte Beantwortung der Nutzereingabe.
Die eingangs formulierte Frage mittels einer gängigen Suchmaschine zu beantworten ist zwar prinzipiell möglich, sollte aufgrund der Auswirkungen auf Menschen (und insbesondere Patienten), jedoch auf einer selbst zusammengestellten Datenbasis mit entsprechendem Domäne-Wissen basieren. Dafür ist ein Information Retrieval (IR) System notwendig. Ein IR-System nutzt die Eingabe der Benutzer zum Abgleich mit Dokumenten in einer Datenbank, um die relevantesten Inhalte zu extrahieren und zu sortieren. Die Suche nach relevanten Inhalten hat sich dabei über Jahre hinweg wenig verbessert und basiert auf lexikalischen Ansätzen wie der statistischen Vorkommenshäufigkeit (z.B. TF-IDF, BM25), der Wortstammrückführung, Entfernung von „irrelevanten Worten“ aber auch simplen (Voll-)Text vergleichen.
Direkte Abgleiche, egal ob bei Schlüsselworten (Keywords), Wortgruppen oder im Volltext, haben ein generelles Problem: Sprache ist nicht eindeutig. Die Suchergebnisse ignorieren inhaltsmäßige Ähnlichkeiten. Verwenden Benutzer nicht „die richtigen Worte“, sondern Synonyme oder thematisch ähnliche Begriffe, kann es schnell zu falschen Ergebnissen kommen. Beispielsweise könnten die Domäne-Inhalte einer Pflege-Einrichtung ausschließlich fachsprachlich vorliegen, was bedeutet, dass in den Texten von „Sonde“, „Katheter“, etc. die Rede ist und der Begriff „Zugang“ gar nicht vorkommt. In diesem Fall kann keine der klassischen Suchmethoden zielgerichtet relevante Inhalte auffinden. Die möglichst große Übereinstimmung von Eingabeworten und verwendeten Begriffen in den Dokumenten der Datenbank ist zwingende Voraussetzung, egal welche lexikalische oder syntaktische Methode Anwendung findet.
Verbesserung mit KI-Methoden
Mit Aufkommen der aktuellen KI-Welle entwickelten sich in den letzten Jahren vielversprechende Ansätze, um dieses Problematik unter Nutzung von Machine Learning, respektive Deep Learning, zu minimieren. Die Einführung von „Transformer“, zu nennen sind hierbei vor allem BERT, XLM, und T5, ermöglichen es, Zusammenhänge von Worten (Ähnlichkeit, Analogie, Thematik) durch neuronale Sprachmodelle darzustellen. Ein solches Modell kann anschließend anhand von Trainingsdaten hinsichtlich eines Lernziels optimiert werden.

In dem hier vorgestellten Fall gilt es, das Sprachmodell für die asymmetrische Suche zwischen einer Frage und beliebig vielen Textpassagen zu verfeinern (fine tuning). Die Suche ist asymmetrisch, weil eine relativ kurze Frage mit einer i.d.R. deutlich längeren Passage bzw. einem Textabsatz auf semantische Nähe untersucht wird. Im Training erlernt das Modell dabei anhand von Daten-Samples, bestehend aus Frage, der richtigen Antwort, einer falschen Antwort sowie einer Bewertung (score), zu priorisieren, welche Zusammenhänge zwischen Frage und Antwort besonders relevant (attentions) sind.
Symmetrische Suche vs. Asymmetrische Suche
Sollen relevante Inhalte bei der symmetrischen Variante gefunden werden, so müssen Eingabesatz und die Sätze der Datenbank ungefähr gleich lang sein. Bestenfalls sind die Sätze sogar gleich aufgebaut, d.h. es wird die Eingabefrage mit ähnlichen Fragen abgeglichen. In einem FAQ-System kann dies hilfreich sein, da FAQs häufig je Textabschnitt mit einer Frage beginnen.
Beispiel: „Wie reinigt man den gelegten Zugang?“ ↔ „Was mache ich bei der Reinigung des Katheters?“
Gilt es relevante Inhalte mit der asymmetrischen Form zu finden, so sollten Eingabesatz und Datenbank-Sätze unterschiedlich lang, wobei dabei normalerweise letztere länger sind. Solche Suchsysteme kommen am häufigsten vor und auch das hier vorgestellte entspricht diesem Ansatz.
Beispiel: „Wie reinigt man den gelegten Zugang?“ ↔ „Der hygienische Umgang mit einem Katheter ist enorm wichtig, um das Infektionsrisiko zu minimieren. Gehen Sie dabei wie folgt vor: (...)“
Training des Modells und Bewertung der Ergebnisse
Die Durchführung des Trainings erfolgt unter Nutzung von Sentence Transformer mit der Margin-MSE-Loss-Methode. Auf Details des Trainings (Parameter, Dauer, Skripte) soll an dieser Stelle nicht eingegangen werden. Alles wissenswerte über den Datensatz und den Trainingsprozess wird ein einem separaten Artikel vorgestellt bzw. können diese Informationen schon jetzt auf Englisch über Huggingface Transformers, der wichtigsten Plattform zur Veröffentlichung von Transformer Modellen, eingesehen werden. Außerdem lässt sich das trainierte Modell von dort herunterladen (https://huggingface.co/PM-AI/bi-encoder_msmarco_bert-base_german).
Gleich nach dem Training ist eine Evaluierung des neu entstandenen Modells nötig. Nach einer Recherche hat sich zunächst der Vergleich zwischen drei Ansätzen angeboten, welcher in Tabelle 1 dargestellt ist.
|
|
Recall@1 |
Recall@10 |
Recall@100 |
|
Unser Modell |
0.5300
|
0.7196
|
0.7360
|
0.3818 |
0.5663 |
0.5986 |
|
0.3196 |
0.5377 |
0.5740 |
Tabelle 1: Ergebnis der Evaluierung. Auf einer Skala von 0.0 bis 1.0 werden die Ansätze nach der Metrik „Recall“ bewertet. Hierbei ist 1.0 der beste Wert.
Im Vergleich schneidet BM25, ein lexikalischer Ansatz, der in der Praxis noch häufig Verwendung findet, am schlechtesten ab. Im Evaluierungs-Datensatz befinden sich schlichtweg zu viele Frage-Antwort-Paare, die nur bei Verständnis von Synonymen und thematischer Ähnlichkeit korrekt miteinander in Verbindung gesetzt werden können. Das Modell von svalabs erlaubt dagegen den direkten Vergleich zwischen zwei sehr ähnlichen Ansätzen, da sowohl svalabs als auch das Modell von senseaition und der TH Wildau Transformer basiert sind. Im Ergebnis schneidet das neue Modell mit einer hervorragenden Performance-Steigerung um 14 Prozentpunkte ab.
Um die Qualität des hier vorgestellten Ansatzes zu untermauern, findet ein weiterer Vergleich mit einem aktuellen State-Of-The-Art Modell statt: Das Entwickler-Team von deepset.ai hat, nach der DPR-Methode, einen Zwei-Stufen-Transformer für Deutsch entwickelt, bei dem Fragen und Texte/Passagen separat behandelt werden. Die erweiterten Ergebnisse sind in Tabelle 2 abgebildet.
|
|
Recall@1 |
Recall@10 |
Recall@100 |
|
Unser Modell |
0.5300
|
0.7196
|
0.7360
|
|
https://huggingface.co/deepset/gbert-base-germandpr-question_encoder & |
0.4828 |
0.6970 |
0.7147 |
0.3818 |
0.5663 |
0.5986 |
|
0.3196 |
0.5377 |
0.5740 |
Tabelle 2: Ergebnis der erweiterten Evaluierung. Auf einer Skala von 0.0 bis 1.0 werden die Ansätze nach der Metrik „Recall“ bewertet. Hierbei ist 1.0 der beste Wert.
Auch wenn die Performance-Steigerung mit ca. 2 Prozentpunkten kleiner ausfällt, ist das Ergebnis dennoch beeindruckend. Denn beim Ansatz von deepset werden zwei Modelle gebraucht, was Arbeitsspeicher und CPU-Leistung doppelt beansprucht und somit höhere Kosten verursacht. Im Produktiveinsatz kann dies entscheidend sein.
Die Ergebniswerte dürfen jedoch nicht als absolute Werte betrachtet werden! Je nach Testdaten und Domäne können die Werte variieren. Dennoch ist die Evaluierung im Vergleich der Ansätze untereinander valide. Übrigens, Experimente haben die Sinnhaftigkeit einer Kombination von BM25 mit Transformer-Modellen bewiesen. Entsprechende Erkenntnisse, KI getriebene Dienste und das technische Know-How bietet Ihnen die sense.AI.tion GmbH über eine eigens entwickelte Cloud-Produktpalette.
Dieses Projekt ist eine Kollaboration zwischen der Technischen Hochschule Wildau und sense.ai.tion GmbH. Sie können uns wie folgt kontaktieren:
-
Philipp Müller (M.Eng.); Autor
-
Prof. Dr. Janett Mohnke; TH Wildau
-
Dr. Matthias Boldt, Jörg Oehmichen; sense.AI.tion GmbH
This work was funded by the European Regional Development Fund (EFRE) and the State of Brandenburg. Project/Vorhaben: "ProFIT: Natürlichsprachliche Dialogassistenten in der Pflege".
![]()
![]()
![]()